-
[Python으로 웹 스크래퍼 만들기] 파이썬 챌린지 8일차Python 2023. 3. 21. 23:56반응형
📕📗📘 수업 진행
5.5 Keyword Arguments
Keyword Arguments는 arguments 자리에 대한 것을 신경을 안 쓰는 대신에 arguments의 이름을 신경쓴다.
[ class_="jobs" 을 사용하는 이유 ]
python fuction안에 수 많은 argument를 가지고 있는데 저런 방식으로 사용할 경우 순서에 상관없이 argument를 사용할 수 있다.즉, class가 job인 section을 다 찾으라는뜻
* class_로 명명하는 이유 : 'class' 이름 중복을 피하기 위함이다.5.6 Job Posts
새로운 내장 기능
len
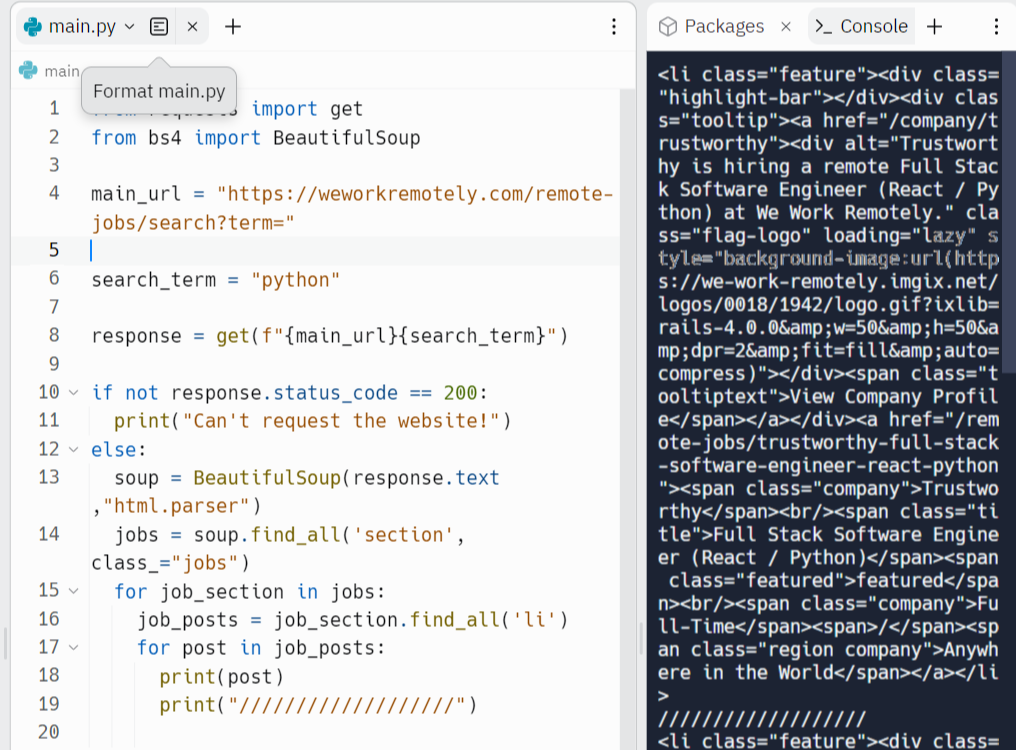
section 안에 있는 모든 li를 가지고 올 것임
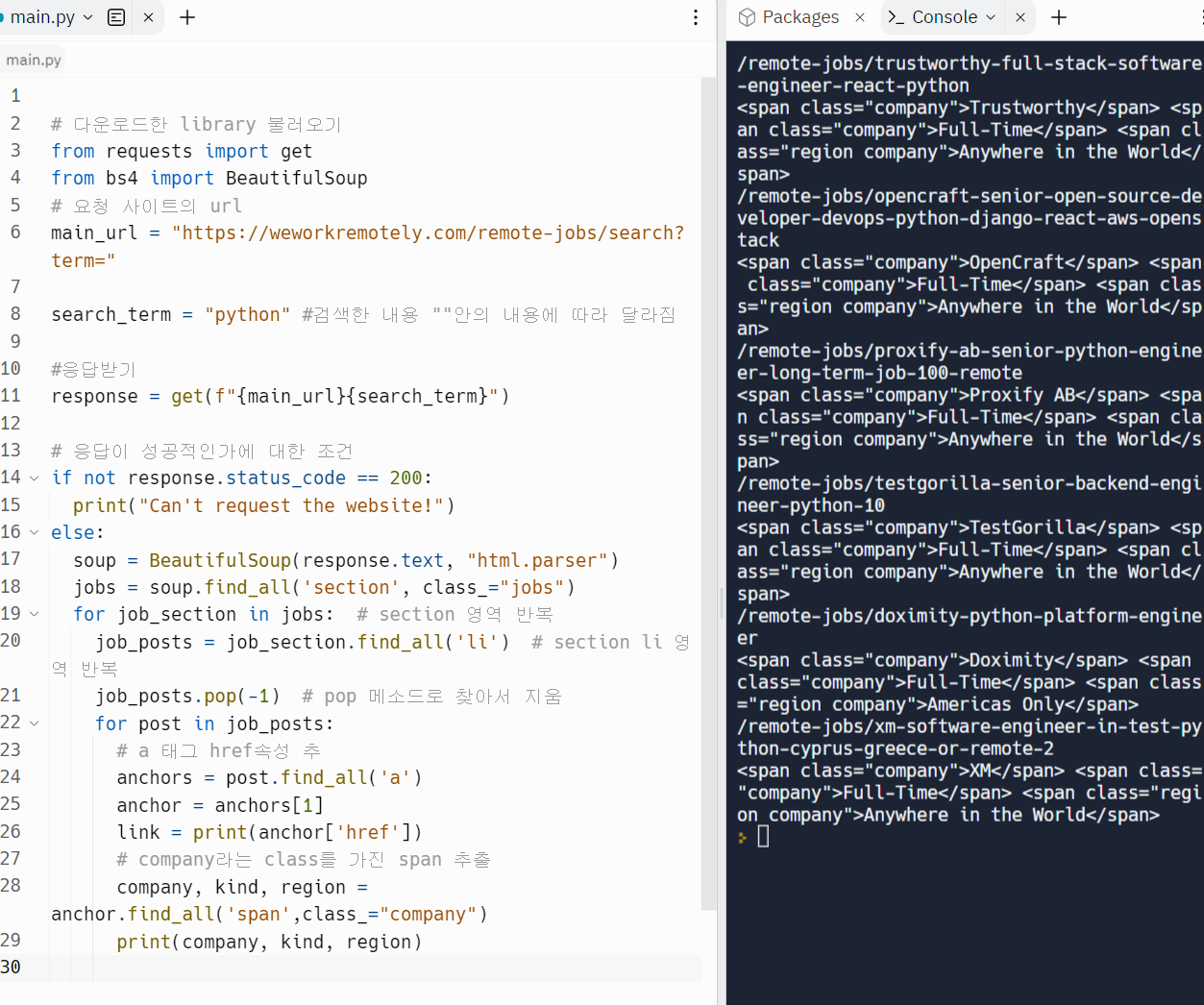
li 요소 불러옴 li의 클래스 중에서 veiw all도 같이 따라 나왔다.(한마디로 필요 없는 요소도 왔다는 것임)
pop.method를 이용을 해서 필요하지 않은 요소 제거

view 클래스 제거함 5.7 Job Extraction
원하는 데이터를 추출 하는법

li의 a 태그 href 속성 추출 find_all_company 영역을 추출 하고 싶다.
company 클래스를 가진 span 영역을 추출 하고 싶다.
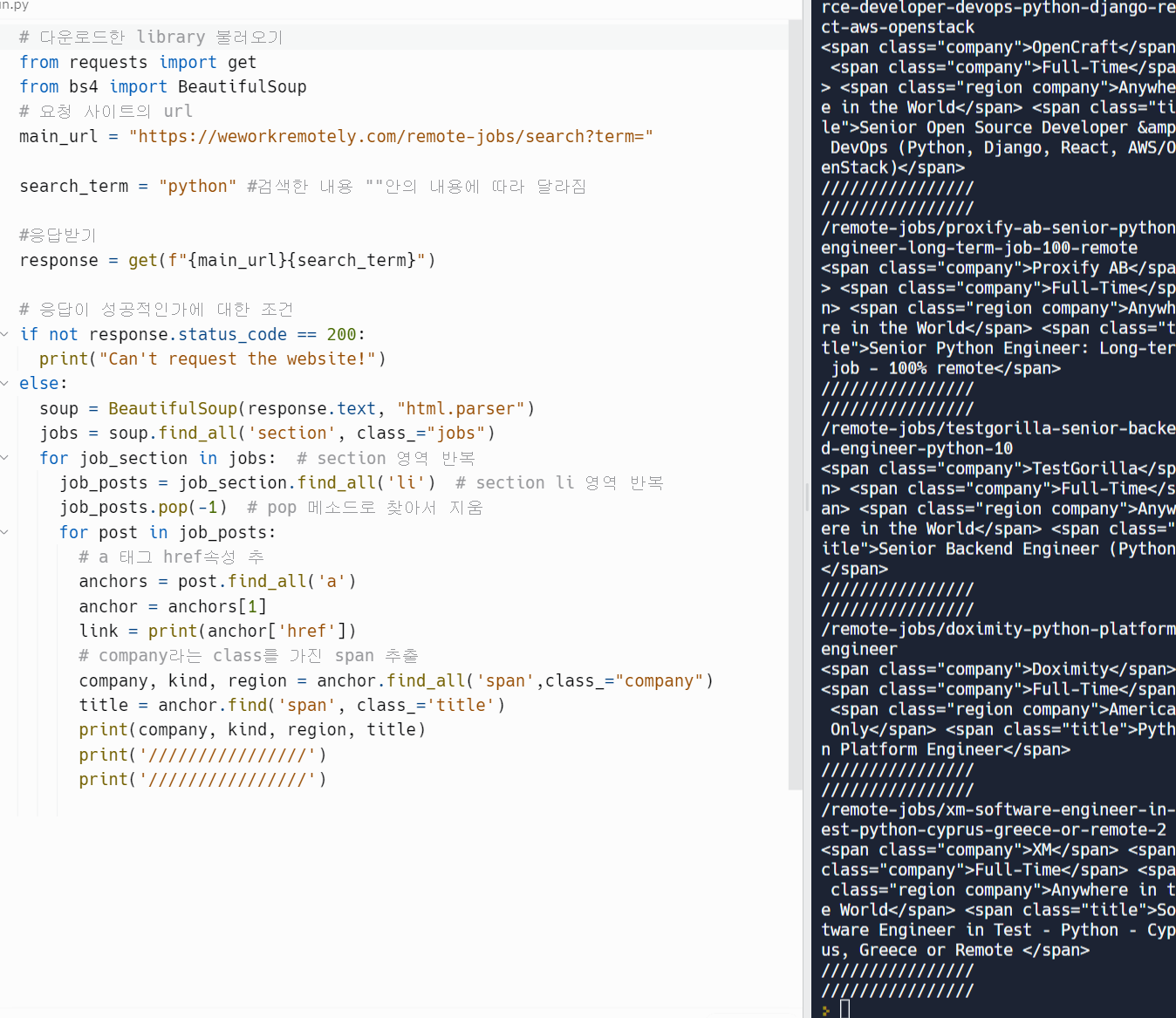
company, kind, region, title 관련 데이터 전부 추출
5.8 Saving Results
텍스트만 따로 추출

.string 메소드 이동 .String 메소드 이용

dictionary로 가득찬 list를 만드는 것 
5.9 Recap
# 다운로드한 library 불러오기 from requests import get from bs4 import BeautifulSoup # 요청 사이트의 url main_url = "https://weworkremotely.com/remote-jobs/search?term=" search_term = "python" #검색한 내용 ""안의 내용에 따라 달라짐 #응답받기 response = get(f"{main_url}{search_term}") # 응답이 성공적인가에 대한 조건 if not response.status_code == 200: print("Can't request the website!") else: results = [] soup = BeautifulSoup(response.text, "html.parser") jobs = soup.find_all('section', class_="jobs") for job_section in jobs: # section 영역 반복 job_posts = job_section.find_all('li') # section li 영역 반복 job_posts.pop(-1) # pop 메소드로 찾아서 지움 for post in job_posts: # a 태그 href속성 추 anchors = post.find_all('a') anchor = anchors[1] link = print(anchor['href']) # company라는 class를 가진 span 추출 company, kind, region = anchor.find_all('span', class_="company") title = anchor.find('span', class_='title') job_data = { # 객체로 저장 'company': company.string, 'region': region.string, 'position': title.string } # append 메소드 이용으로 마지막에 요소 추 results.append(job_data) for result in results: print(result) print("///////"){'company': 'Trustworthy', 'region': 'Anywhere in the World', 'position': 'Full Stack Software Engineer (React / Python)'} /////// {'company': 'OpenCraft', 'region': 'Anywhere in the World', 'position': 'Senior Open Source Developer & DevOps (Python, Django, React, AWS/OpenStack)'} /////// {'company': 'Proxify AB', 'region': 'Anywhere in the World', 'position': 'Senior Python Engineer: Long-term job - 100% remote'} /////// {'company': 'TestGorilla', 'region': 'Anywhere in the World', 'position': 'Senior Backend Engineer (Python)'} /////// {'company': 'Doximity', 'region': 'Americas Only', 'position': 'Python Platform Engineer'} /////// {'company': 'XM', 'region': 'Anywhere in the World', 'position': 'Software Engineer in Test – Python – Cyprus, Greece or Remote '} ///////반응형'Python' 카테고리의 다른 글
[Python으로 웹 스크래퍼 만들기] 파이썬 챌린지 7일차 (0) 2023.03.20 [Python으로 웹 스크래퍼 만들기] 파이썬 챌린지 6일차 (0) 2023.03.18 [Python으로 웹 스크래퍼 만들기] 파이썬 챌린지 5일차 (1) 2023.03.17 [Python으로 웹 스크래퍼 만들기] 파이썬 챌린지 4일차 (0) 2023.03.16 [Python으로 웹 스크래퍼 만들기] 파이썬 챌린지 3일차 (0) 2023.03.15